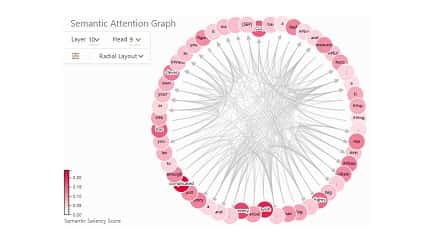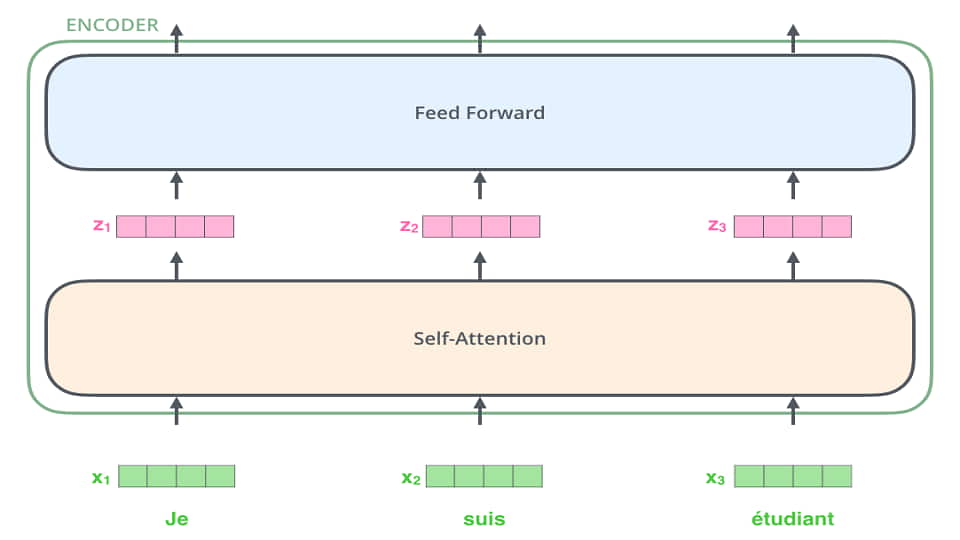
پیش از این به ایده ترنزفرمرها اشاره کرده بودیم. در این سلسله نوشتار قصد بیان این موضوع را داریم که چرا ترنزفرمرها ساختار بسیار مناسبی برای مسائل مربوط به پردازش زبان طبیعی هستند. اشاره کرده بودیم که ایده اصلی در ترنزفرمرها روی weight sharing و ضرب داخلی بنا شده است. این ساختار سبب می شد که این مدلها ساختار مناسبی برای موازی سازی باشند و ضعف ذاتی شبکه های بازگشتی را نداشته باشند؛ با این حال، یک موضوع دیگری که در این شبکه ها وجود دارد، بعد از انجام ضرب داخلی خود را نشان می دهد. تصور کنید که تعامل (interaction) یک کلمه با سایر کلمات را پیدا کرده اید و می خواهید مقدار نهایی را بدست آورید. به این صورت است که با توجه به وزنهایی که برای کلمات مختلف بعد از ضرب کردن بدست آورده اید، تمامی کلمات شرکت داده می شوند. بعضی ها خیلی کم، بعضی ها کم و بعضی زیاد. ما برای هر کلمه لازم است تعاملات را بدست آوریم و یک بردار نهایی حاصل کنیم؛ به عبارتی دیگر، سعی می کنیم برای هر کلمه یک word embedding جدید با توجه به context پیدا کنیم؛ یعنی اگر از میانه، شبکه را نگاه کنیم، embedding بدست آمده برای هر کلمه دیگر ثابت نیست، برخلاف روشهایی مثل word2vec، و بردار حاصل برای هر کلمه با توجه به کلمات اطرافش بدست می آید.
چرا این موضوع اهمیت دارد؟ پاسخ به یک موضوع زبان شناختی باز می گردد. در زبانهای انسانی، ممکن است کلمات، شکل ظاهری یکسان داشته باشند ولی با توجه به context مفهوم متفاوتی داشته باشند. دو جمله پایین را در نظر بگیرید:
- علی شیر آب را بست.
- علی از شیر نمی ترسد.
در هر دو جمله از کلمه شیر استفاده شده است ولی می دانیم که معانی متفاوتی دارند؛ با این حال، در روشهایی مثل word2vec بردار هر دو شیر یکسان است ولی در روشهای مربوط به ترنزفرمر، پس از اعمال محاسبات، بردار شیر اول لزوما مثل شیر دوم نخواهد بود و هر کدام از بردارها با توجه به context استخراج می شوند.
پیدا کردن تعاملات به این شکل یک مزیت دیگر هم دارد. چرا برای هر کلمه فقط یک بردار پیدا کنیم؟ شاید کلمات وابستگی ها و تعاملات متفاوتی داشته باشند. در جمله اول با کمک شیر، بستن و آب یک انسان متوجه می شود که منظور شیر جنگل نیست. با این حال ممکن است بخواهیم علاوه بر این موضوع تعاملات دیگری را نیز "نهفته" کنیم؛ برای مثال، مطابقت فعل و فاعل. اینجاست که بحث داشتن multi head پیش می آید و می توانیم چند embedding برای هر کلمه پیدا کنیم تا تعاملات متفاوت را پیدا کنیم.